Prompt
A Prompt column allows you to define a custom prompt and run it directly on your Playground data. You can compose prompts with messages (system, user, assistant or developer), insert playground variables, and configure which model to use. Each row in your playground will be passed through the prompt, and the model’s response will be stored in the column.Prompt columns make it easy to test different prompts against real data, compare model outputs side by side.
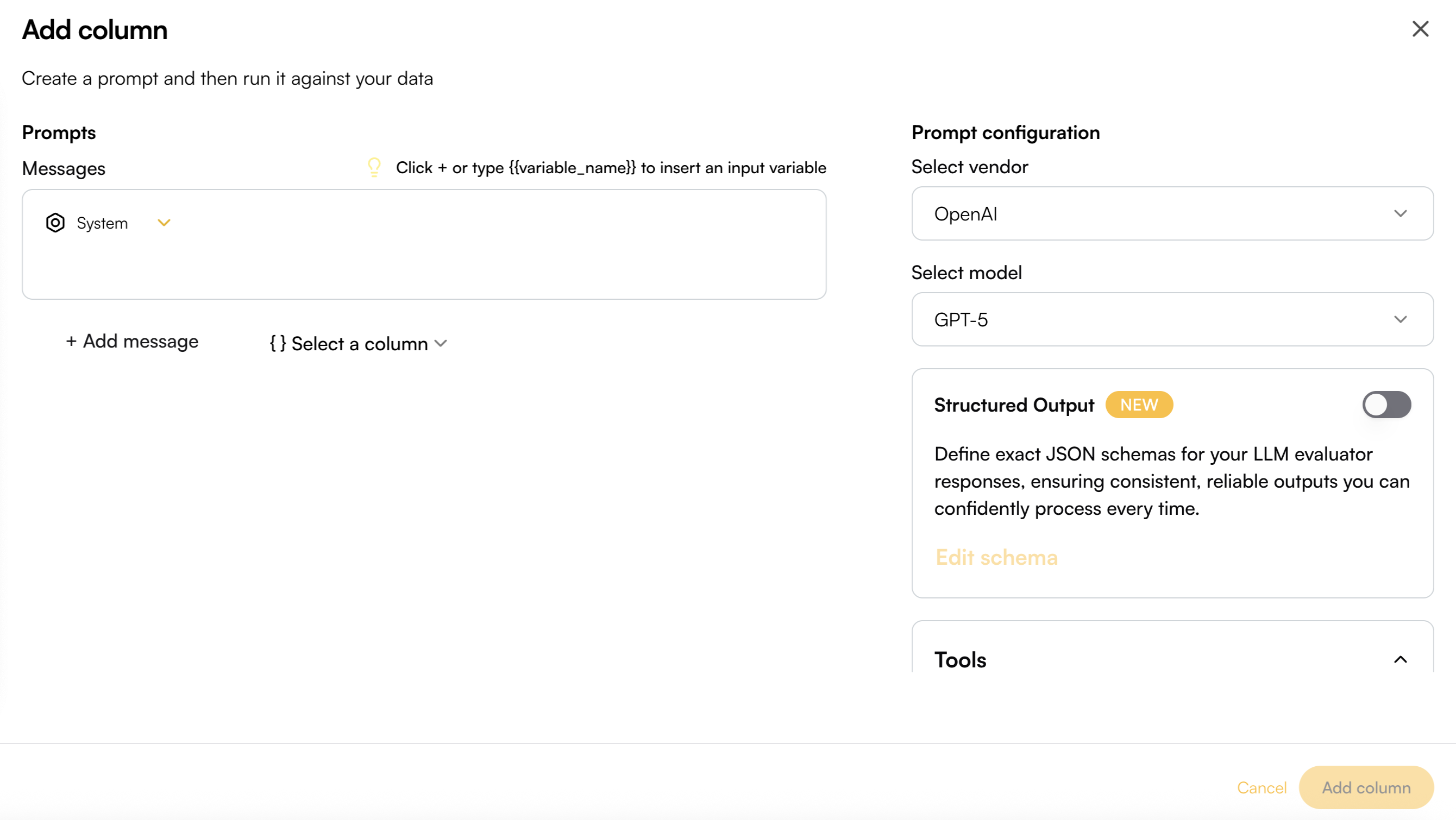
Prompt Writing
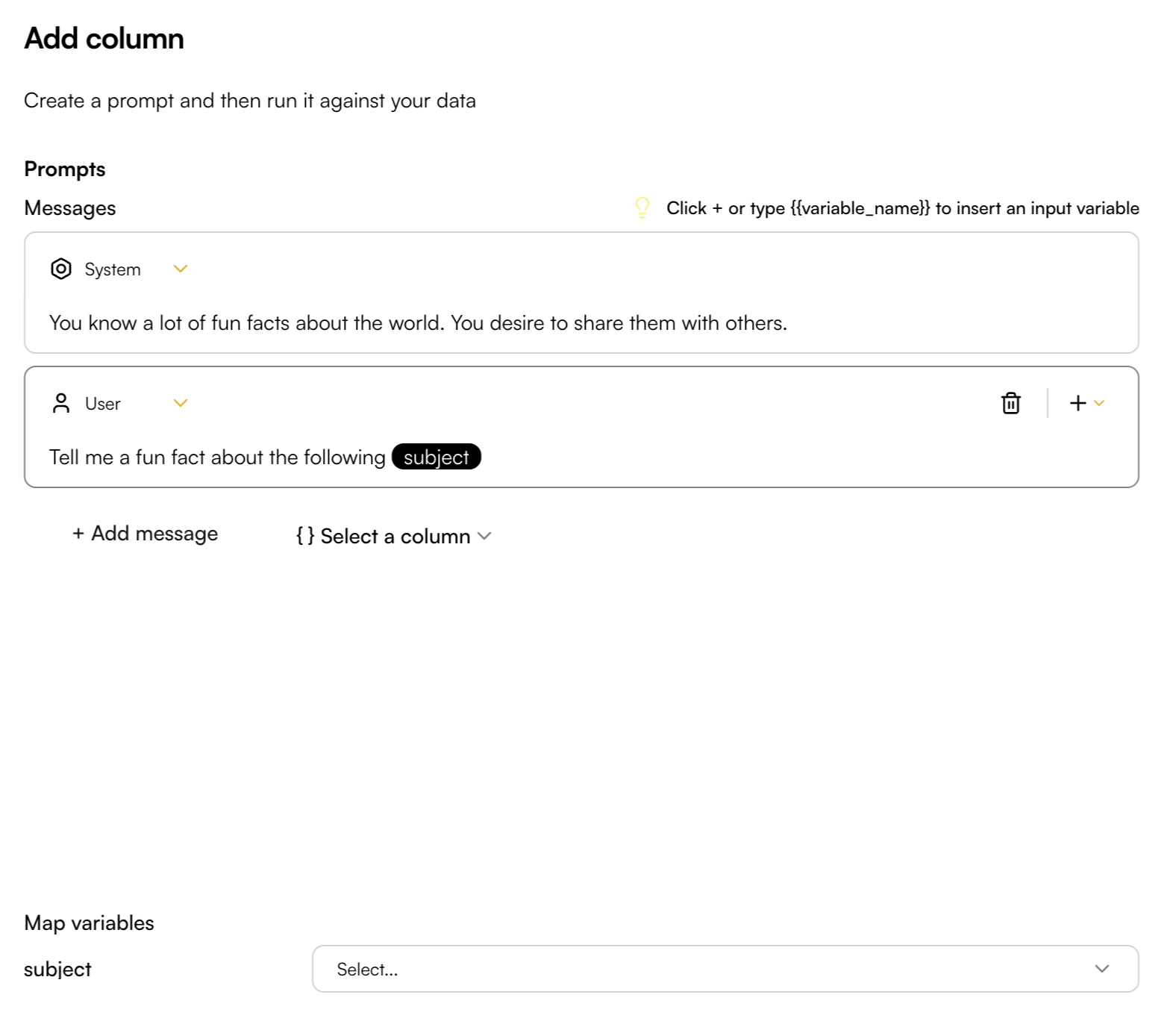
Write your prompt messages by selecting a specific role—System, User, Assistant, or Developer. You can insert variables into the prompt using curly brackets (e.g.,{{variable_name}}) or by adding column valuable with the top right + button in the message box. These variables can then be mapped to existing column data, allowing your prompt to dynamically adapt to the playground
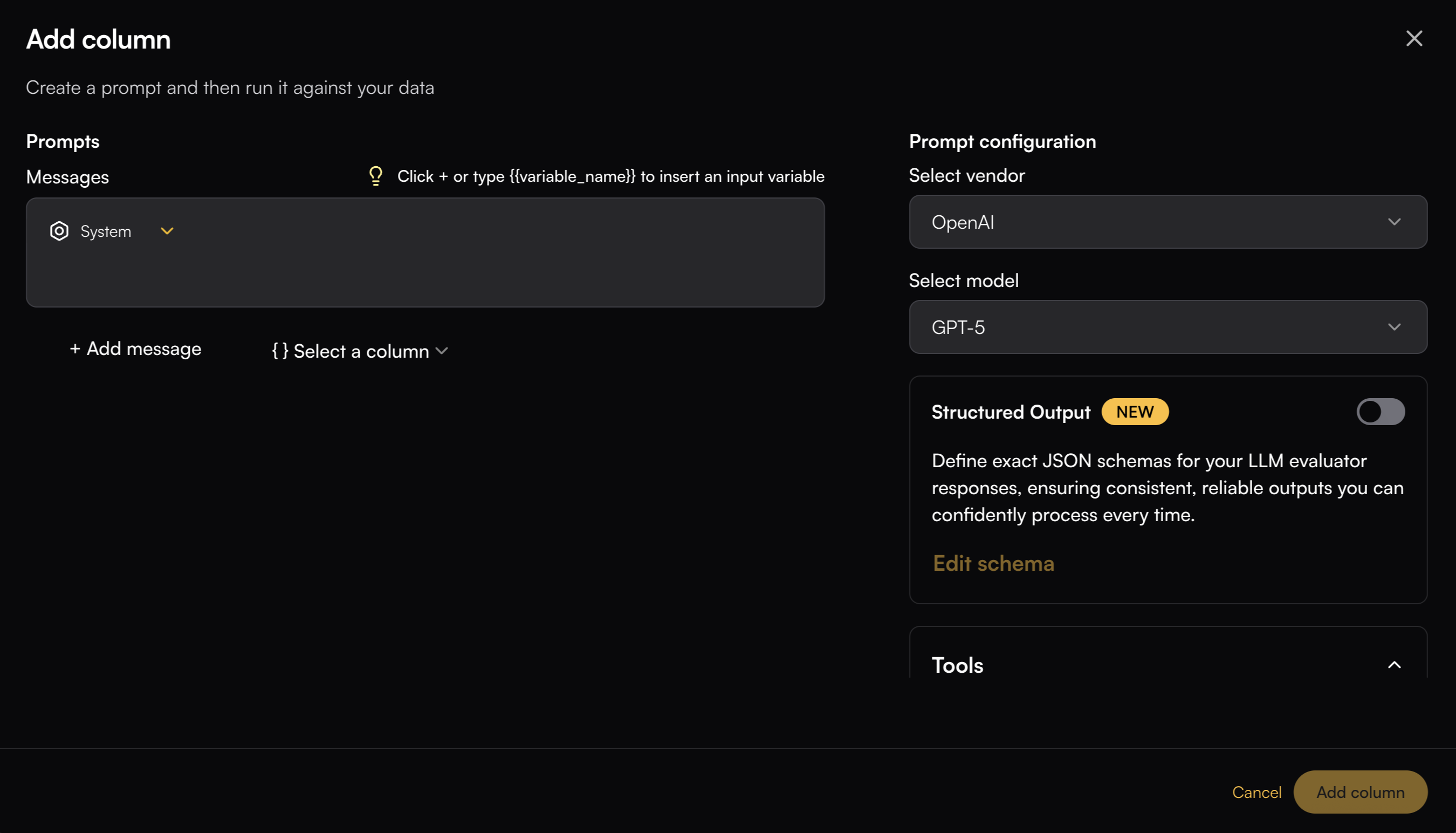
Configuration Options
Model Selection
You can connect to a wide range of LLM providers and models. Common choices include OpenAI (GPT-4o, GPT-4o-mini), Anthropic (Claude-3.5-Sonnet, Claude-3-Opus), and Google (Gemini-2.5 family). Other providers such as Groq and DeepSeek may also be supported, and additional integrations will continue to be added over time.Structured Output
Structured output can be enabled for models that support it. You can define a schema in several ways:- JSON Editor - Write a JSON structure directly in the editor
- Visual Editor - Add parameters interactively, specifying their names and types
- Generate Schema - Use the “Generate schema” button on the top right to automatically create a schema based on your written prompt
Tools
Tools let you extend prompts by allowing the model to call custom functions with structured arguments. Instead of plain text, the model can return a validated tool-call object that follows your schema. To create a tool, give it a name and description so the model knows when to use it. Then define its parameters with a name, description, type (string, number, boolean, etc.), and whether they are required.Advanced Settings
Fine-tune model behavior options:- Temperature (0.0-1.0): Control randomness and creativity
- Max Tokens: Limit model output length (1-8000+ depending on model)
- Top P: Nucleus sampling parameter (0.0-1.0)
- Frequency Penalty: Reduce repetition (0.0 to 1.0)
- Presence Penalty: Encourage topic diversity (0.0 to 1.0)
- Logprobs: When enabled, returns the probability scores for generated tokens
- Thinking Budget (512-24576): Sets the number of tokens the model can use for internal reasoning before producing the final output A higher budget allows more complex reasoning but increases cost and runtime
- Exclude Reasoning from Response: If enabled, the model hides its internal reasoning steps and only outputs the final response