
A Comprehensive Guide to Tokenizing Text for LLMs


In natural language processing (NLP), large language models (LLMs) like BERT, Claude, and GPT have become prominent, as they push the boundaries of language understanding and text generation.
But have you ever wondered how machines can generate impressive blocks of text that seem to have been generated by a human? A well-trained text generation model can make it really hard to differentiate between human-written and machine-generated text.
Tokens, the smaller units in LLMs’ vocabularies, are the basis of these models’ linguistic abilities. In this article, we’ll explore the tokenization process, its different algorithms, and the potential pitfalls inherent in tokenization.
What Is Tokenization?
The tokenization process involves dividing input text and output text into smaller units, known as tokens, suitable for processing by LLMs. Tokens can be words, subwords, characters, or symbols, depending on the model's type and size.
Tokenization enables LLMs to navigate different languages, formats, and vocabularies, reducing computational and memory costs.
Why Do We Need to Tokenize?
Tokenization plays an essential role in shaping the quality and diversity of generated text, by influencing the meaning and context of the tokens in LLMs. In addition to text segmentation, it optimizes resource usage, expedites processing, and facilitates adept management of linguistic complexes.
Essential for contextual understanding, tokenization improves an LLM's effectiveness in tasks like summarization and translation — with acknowledged limitations such as language bias and dialect challenges.
You need tokenization for the following reasons:
Structuring Data: Tokenization transforms unprocessed text into a framework that enhances algorithmic comprehension.
Enhanced Efficiency: By fragmenting text into smaller units, tokenization streamlines the text processing process for LLMs, boosting overall efficiency.
Foundational Features: Tokenized text forms the groundwork for extracting features, a vital aspect in empowering machine learning models for accurate predictions and decisions.
Preserving Context: A skillfully executed tokenization preserves the contextual ties between words. This proves invaluable in complex tasks such as sentiment analysis, translation, and summarization.
Tokenizing Algorithms
Here are some important types of tokenization algorithms:
1. Whitespace Tokenization
Algorithm: This tokenizer uses whitespace characters such as spaces, tabs, and newlines to separate words. It's a simple method that doesn't consider linguistic structures, often used as a baseline tokenizer in text processing.
Example: "Hello, World" → ["Hello", "World"]
2. Sentence Tokenization
Algorithm: Sentence tokenization involves using punctuation and context to break text into sentences. It helps in higher-level language understanding by dividing text into meaningful units. It also aids in various NLP tasks such as sentiment analysis and machine translation.
Example: "This is a sentence. And this is another." → ["This is a sentence.", "And this is another."]
3. Word Tokenization
Algorithm: The word tokenizer uses language-specific rules to segment text into individual words. It takes into account common word delimiters like spaces and punctuation marks, providing a fundamental approach for processing natural language text.
Example: "This is a programmer." → ["This", "is", "a", "programmer"]
4. Byte Pair Encoding (BPE)
Algorithm: BPE is a data compression technique that is applied in tokenization by merging frequently occurring pairs of characters. This process creates a vocabulary of subword units, effectively representing words and enabling the handling of rare or out-of-vocabulary terms.
Example: Given the input text "abracadabra," BPE might iteratively merge the most frequent character pairs, resulting in subword units like {"abrc", "a", "d", "ab", "r", "c"}. Tokenizing the original text using this vocabulary yields ["abrc", "a", "d", "a", "br", "a"].
5. Subword Tokenization
Algorithm: Subword tokenization breaks down words into smaller units, allowing the model to handle unseen words and improve generalization. It is commonly employed in neural machine translation and other tasks where subword representations are beneficial.
Example: "unhappiness" → ["un", "happi", "ness"]
6. Tokenization Using Regular Expressions
Algorithm: This method utilizes predefined patterns encoded in regular expressions to tokenize text. It is a flexible approach that allows customization based on specific tokenization rules, making it suitable for tasks with unique text processing requirements.
Example: "abc123xyz" → ["abc", "123", "xyz"]
7. Maximum Matching Tokenizer
Algorithm: The maximum matching tokenizer segments text by selecting the longest possible match from a dictionary. It is often employed in languages with limited word boundaries, providing a heuristic-based approach to tokenization.
Example: "applepie" → ["apple", "pie"]
8. Treebank Tokenizer
Algorithm: The Treebank tokenizer adheres to the conventions outlined in the Penn Treebank, a widely used corpus in NLP. It tokenizes text based on grammatical structures, helping maintain consistency in tokenization across various applications.
Example: "It's raining cats and dogs." → ["It", "'s", "raining", "cats", "and", "dogs", "."]
Leveraging Tokenized Text for Evaluation
Tokenization is an initial critical step in preparing data for LLMs, because these models process numerical data and do not understand raw text. The role of the tokenizer is to convert raw text into numbers that a model can understand.
Here is a step-by-step explanation of how the process works:
1. Input Text
Start with the text you need to input into the model for processing — for instance, "Prompt tuning is fun for me!"
2. Tokenization
The model breaks the text into tokens (words, parts of words, or characters, depending on the tokenizer's design).
Word Tokenization → "Prompt", "tuning", "is", "fun", "for", "me", "!"
Subword Tokenization → "Prompt", "tun", "##ing", "is", "fun", "for", "me", "!"
(The “##” shows that “ing” is part of the previous token.)
3. Token IDs
Each token is mapped to a unique ID depending on the vocabulary file used by the tokenizer. The file has a list of all tokens known to the model, and each of them has a unique ID.
Example: [ Prompt → 35478, tun → 13932, ing → 278, is → 318, fun → 1257, for → 329, me → 483, ! → 0 ]
4. Encoding
Encoding is the process of converting a token into a token ID. The sentence "Prompt tuning is fun for me!" would be encoded as [35478, 13932, 278, 318, 1257, 329, 483, 0].
5. Model Processing
These IDs are fed into the LLM, which helps them perform tasks like answering questions, translation, and text generation.
6. Decoding
During text generation, the model outputs token IDs that are converted back to human-readable text.
It's important to use the right tokenizer to ensure that the text is tokenized in a way your model has been trained to decode.
Understanding the ChatGPT Tokenizer
To understand the process better, let's take the example of ChatGPT. Have you ever wondered how ChatGPT by OpenAI takes the user prompts?
Well, we all assume that ChatGPT predicts the next word. However, it doesn't predict the next word; it predicts the next token.
One of the initial steps that ChatGPT takes when processing any prompt is breaking down the user input into tokens. It's done with the help of a tokenizer.
The ChatGPT tokenizer uses the original library by OpenAI, the tiktoken library.
Language Model Tokenization in ChatGPT
OpenAI LLMs, known as GPTs, process text using tokens. The model learns the statistical relationship between the tokens and generates the next token in a sequence of tokens.
Here is OpenAI's tokenizer, a tool to demonstrate how a language model can tokenize a piece of text. It also generates the unique token ID for each token.
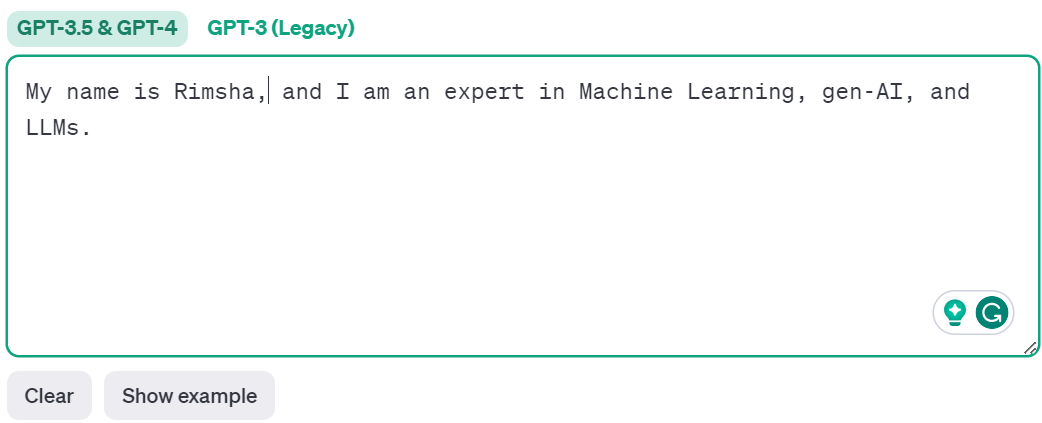
The model split the text into 25 tokens and 77 characters.

It also generates a unique token ID for each token.

It's important to note that the tokenization process varies between models.
How to Use Tokenization for Text Evaluation
For evaluating text quality using tokenization and the similarity distance of tokenized vectors, let's use the popular NLP library spaCy. By using this library, we will create the text's vector representation and then calculate the similarity index between the vectors. Here is a step-by-step guide:
1. Install and Import the SpaCy Library
Install the spaCy library using the command 'pip install spacy', and then import it into your script or notebook.
import spacy
2. Load SpaCy Model
Load a pre-trained model including the word vectors — for instance, the 'en_core_web_md' model.
nlp = spacy.load ("en_core_web_md")
3. Tokenize and Vectorize Texts
Next, tokenize the input text and convert it into vector representation using spaCy.
SpaCy's NLP object can be used to tokenize the text.
text1 = "tokenize the text"
text2 = "vectorize the text"
# Tokenize using spaCy
doc1 = nlp(text1)
doc2 = nlp(text2)
Here, doc1 and doc2 are spaCy 'Doc' objects that represent a tokenized version of the relevant text.
Vectorization: 'en_core_web_md' has vectors that contain semantic information regarding texts. You can access these vectors via the '.vector' attribute for each token in the 'Doc' object.
# Accessing vectors for each token
vector1 = doc1.vector
vector2 = doc2.vector
4 Calculate the Similarity Distance
Use the '.similarity()' method to calculate the cosine similarity between vectors. Cosine similarity ranges from -1 to 1 (completely dissimilar to identical).
# Calculate cosine similarity
similarity_score = doc1.similarity(doc2)
print("Similarity Score:", similarity_score)
If you have multiple pieces of text to compare, repeat the process for each pair.
You can evaluate the semantic similarity of text based on their vector representation by leveraging spaCy's tokenization and vectorization capabilities. Adjustments can be made depending on a specific evaluation criterion and use case.
Use Cases of Tokenization
Tokenization is a critical step in many NLP tasks for various reasons. These include:
- Text Understanding: Tokens split the text into manageable chunks that machines can process. This process helps them understand the meaning and structure of text.
- Language Modeling: Tokens are used as the vocabulary of language models that predict the next token in a sequence. This process makes tokens the basic element in text generation and completion.
- Text Classification: In NLP tasks like spam detection or sentiment analysis, tokens play a vital role in determining the content of text by analyzing words or subwords within it.
- Machine Translation: Tokens allow text translation from one language to another. The machine translation system converts the source language's tokens into the target language's tokens.
- Named Entity Recognition: Tokens are also crucial for NER tasks where entities like dates, locations, and names need to be identified in the text. Each entity is represented as a set of tokens.
Pitfall: Tokenization Variability
While tokens are the basic units for the model to understand language, seamless tokenization may have its challenges.
Let's explore the problems in tokenization, giving you a closer look at issues that can affect how well the model works.
1. ID Assignment Inconsistency
Tokenization may exhibit inconsistency in assigning IDs, impacting the model's understanding of different inputs. For instance, "John" might be a single token number [12334] in GPT, but "John Rickard" could be encoded as three separate tokens, “John,” “Rick,” and “ard,” with distinct IDs [12334, 7895, and 664].
This is perhaps because "John" is common enough to be a token in GPT-3's 14 million string vocabulary, while "Rickard" is not as frequently used.
2. Case Sensitivity
Tokenization treating cases differently can lead to challenges in recognizing the equivalence of words with distinct letter cases. Case sensitivity introduces distinctions between tokens.
For instance, "hello" might be represented as [745], "Hello" as [392], and "HELLO" as three separate tokens [65131, 1209, and 28] ("HE", "EL", and "O").
3. Inconsistent Digit Chunking
Inconsistencies in digit chunking during tokenization can impact tasks involving numbers and mathematical operations. The tokenization of numbers can be inconsistent.
For instance, "12o" might be tokenized as a single entity in GPT, but "124" could be represented as two tokens [“12” and “4”]. This irregular digit handling influences tasks related to mathematics and word manipulation.
4. Trailing Whitespace Impact
Tokenization's sensitivity to trailing whitespace can influence the subsequent token prediction and completion behavior of the language model.
Consider the impact of trailing whitespace: "in a forest " is tokenized as separate units [“in”, “ a”, “ forest”, “ ”], whereas "in a forest clearing" is encoded differently [“in”, “ a”, “ forest”, “ clearing”]. This difference affects the probability of the next token due to the inclusion of whitespace.
5. Model-Specific Tokenization
Tokenization methods vary across models, even when they employ the same technique, leading to complications in preprocessing and multi-modal modeling.
Tokenizers tailored for specific models, such as Model A and Model B, differ despite using a common method like byte pair encoding. This model-specific tokenization introduces complexities in pre-processing and hinders seamless multi-modal modeling.
Are Metrics Like ROUGE and BLEU Better Than Tokenization for Text Evaluation?
Metrics like BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are used for specific purposes in text evaluation, and we have discussed that in previous posts. Though tokenization has some limitations, we can't exactly say that ROUGE and BLEU are inherently better than tokenization. However, they address different aspects of the text evaluation process.
- ROUGE and BLEU have a better contextual understanding, as they consider the context of an entire sentence. However, tokenization treats each word or subword in isolation, potentially overlooking the relationship between words and their contextual nuances.
- Both these metrics go beyond tokenization by evaluating the fluency and coherence of the generated text. However, tokenization mainly focuses on local patterns within a text, which may not capture the overall fluency and coherence of longer sentences.
- BLEU and ROUGE are suitable for tasks like machine translation and text summarization, where the quality of all of the generated text is important. However, tokenization is mainly used in tasks such as NLP, machine learning, and feature extraction, where understanding the local patterns and their relationships is essential.
- These metrics provide a high-level evaluation of the generated text's quality. However, tokenization acts as an essential pre-processing step, splitting the text into manageable pieces for feature extraction and further analysis.
Final Words
Tokenization is a fundamental process of NLP; it bridges the gap between human and machine understanding. In this article, we’ve discussed the tokenization process, its different algorithms, how it helps in text evaluation, and how it compares with different metrics like ROUGE and BLEU. With this information and knowledge, you are ready to navigate the NLP world and harness its capabilities for text evaluation and generation. Tokens may be small, but their impact is huge in the field of NLP.











